A preview of Ezno's checker
The big news
Ezno's checker has now been open-sourced!
This post is an overview of the current status of the project and goes into more detail about its unique approach to type-checking!
The aims/direction of the project
Two things:
- It is not aimed at having one-to-one parity with TSC. I made the point last year that TypeScript's implementation of
any(and its other backdoor behaviours) make doing type-based optimisations and complete type safety impossible. In my opinion, 90% of TSC features' are great, so the aim is to be able to use existing syntax and not to break things in a bad ways. - Following on from 1) this is an experimental project. I want to explore new techniques and make previously impossible things possible! Building it from scratch makes it a lot more fun and easier to build for me.
There is still a lot to do, a lot of JS features are still unimplemented. I am only human :smile:, while I can implement features quickly, some other things will require time (also not to overwhelm myself).
Checking performance
Don't want to dwell too much, there are a lot of places where Ezno could be faster I just haven't had the time to improve and the project is not at a stable place to work on optimising current behaviour. However I have seen a few comments that "Ezno does more, so will be slower", so I did some investigating and have some pretty interesting numbers:
Benchmark 1: oxidation-compiler check ./demo.ts
Time (mean ± σ): 48.5 ms ± 1.4 ms [User: 33.6 ms, System: 15.0 ms]
Range (min … max): 46.6 ms … 55.4 ms 60 runs
Benchmark 2: tsc --pretty demo.ts
Time (mean ± σ): 1.658 s ± 0.165 s [User: 2.364 s, System: 0.103 s]
Range (min … max): 1.542 s … 2.110 s 10 runs
Summary
oxidation-compiler check ./demo.ts ran
34.21 ± 3.55 times faster than tsc --pretty demo.ts
Benchmark 1: oxidation-compiler check ./demo.ts
Time (mean ± σ): 48.5 ms ± 1.4 ms [User: 33.6 ms, System: 15.0 ms]
Range (min … max): 46.6 ms … 55.4 ms 60 runs
Benchmark 2: tsc --pretty demo.ts
Time (mean ± σ): 1.658 s ± 0.165 s [User: 2.364 s, System: 0.103 s]
Range (min … max): 1.542 s … 2.110 s 10 runs
Summary
oxidation-compiler check ./demo.ts ran
34.21 ± 3.55 times faster than tsc --pretty demo.ts
These are rough benchmarks, so take these numbers with a grain of salt, they could go up or down. You can see the full result in my fancy automated benchmarking repository
STC: Speedy type checker
Ezno is not the only TS checker written in Rust. STC (which was made public last year) is aimed at following TSC one-to-one, with the aim of improving the type checking time compared to TSC. Similar to Ezno in still being work in progress. Its current results look very impressive, being slightly faster than Ezno with Oxc.
./stc/target/release/stc test demo.ts ran
2.72 ± 0.11 times faster than oxidation-compiler check ./demo.ts
89.80 ± 3.56 times faster than tsc --pretty demo.ts
./stc/target/release/stc test demo.ts ran
2.72 ± 0.11 times faster than oxidation-compiler check ./demo.ts
89.80 ± 3.56 times faster than tsc --pretty demo.ts
Architecture of a type checker
A compiler is typically a chain of the following processes
lexing -> parsing -> type synthesis & checking -> output
lexing -> parsing -> type synthesis & checking -> output
Ezno's current approach type synthesis & checking is a bit different from others, so here is some more insight.
Synthesis: a bridge between the system and the language
The main ezno-checker system contains high-level memory of the program (it's sort of its heap), it stores all the information about values and structures (encoded as types) and what functions and blocks do (encoded as events). This is all currently done in the ezno-checker crate.
Synthesis on the other hand is taking AST and forming types from it.
Due to some issues with Ezno's own parser and after an offer to help from Boshen I figured it would be a good idea to make the synthesis work under other AST crates. To do this required some changes to split the checker logic from AST synthesis and the creation of a new bridge crate between Oxc AST and Ezno checker.
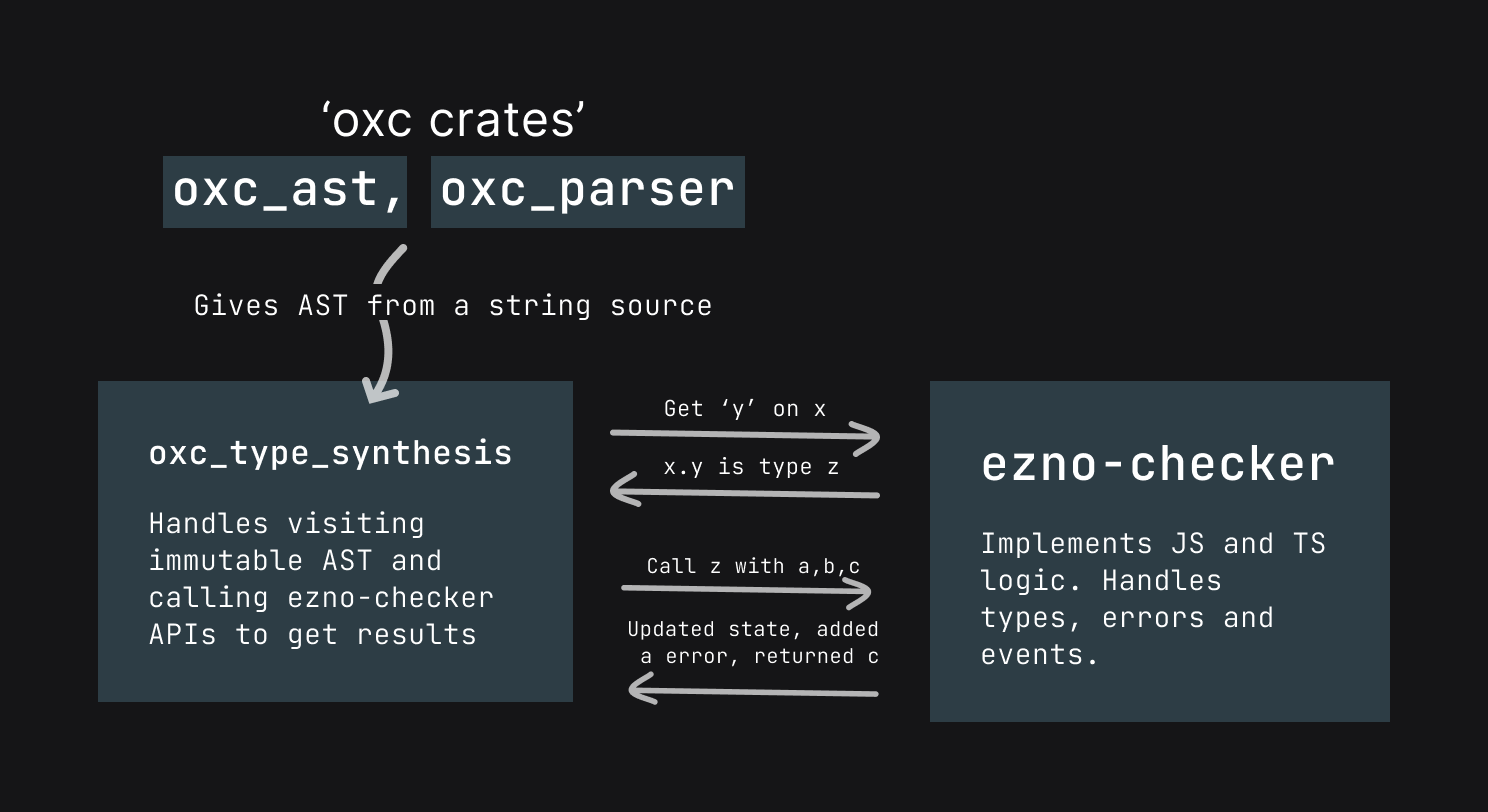
The bridge crate consists of things like code that turns oxc_ast::ast::Expression into a type
pub(crate) fn synthesize_expression<T: FSResolver>(
expr: &ast::Expression,
environment: &mut Environment,
checking_data: &mut CheckingData<T>,
) -> TypeId {
let instance = match expr {
ast::Expression::BooleanLiteral(boolean) => {
return checking_data
.types
.new_constant_type(ezno_checker::Constant::Boolean(boolean.value));
}
ast::Expression::NullLiteral(_) => return TypeId::NULL_TYPE,
...
pub(crate) fn synthesize_expression<T: FSResolver>(
expr: &ast::Expression,
environment: &mut Environment,
checking_data: &mut CheckingData<T>,
) -> TypeId {
let instance = match expr {
ast::Expression::BooleanLiteral(boolean) => {
return checking_data
.types
.new_constant_type(ezno_checker::Constant::Boolean(boolean.value));
}
ast::Expression::NullLiteral(_) => return TypeId::NULL_TYPE,
...
Thanks to this, a check command was added to Oxc CLI and type checking was added to the playground.
The playground is currently work in progress as I only added support in an a hour, expect some crashes that will show up in the browser console
As Oxc has an incredibly fast and correct parser it will be a great way to use Ezno's checker!
This isn't the end of Ezno's own parser and CLI. It was incredibly useful building it, and it's 95% of the way there. It is great that the bindings exist with Oxc to offer a fast and reliable option to use Ezno's checker.
An interpreter-based checker
Ezno tackles type-checking as evaluator/interpreter. However, unlike a real JS interpreter rather than passing around values it passes around types. These are instead spaces that values live in.
Evaluation

Type-based evaluation

Some big differences between what a value-based interpreter would be and Ezno's evaluator-based type checker:
- Control flow has to handle different cases. In standard evaluation branches are binary, they either run or they don't run. In Ezno's checker, it's non-deterministic. (unless it can find the branching condition to be
true) It has to evaluate both branches and join the results together. Similarly, loops (and recursion) have undecidability to them and have to unify the results to reflect the possible amount of times the block can run. - IO functions don't run. It doesn't make
fetchrequests orMath.random()at compile time, and it certainly doesn't ask the compiler's user to answer toprompt. But all other functions whether from the runtime or user code are evaluated in some kind. It does the evaluations (most of the time) based on the body of a function, rather than a return type annotation.
The other big difference between an interpreter is that it type checks annotations. While there is no rule that interpreter cannot do this, it doesn't hugely make sense
This approach has benefits for languages with dynamic features. However, this approach still has benefits for stricter languages.
I have a longer, more theoretical post on some additional points, which I will get around to finishing at some point 😀
Less theory, let's see how it works. The next part goes over some code that is used in the current demo. You can try the above first to see how it is implementation works.
Inside the checker and its features
Note that a lot of this is a work in progress and things might have changed after the publishing of this post.
Contexts
Contexts store local information.
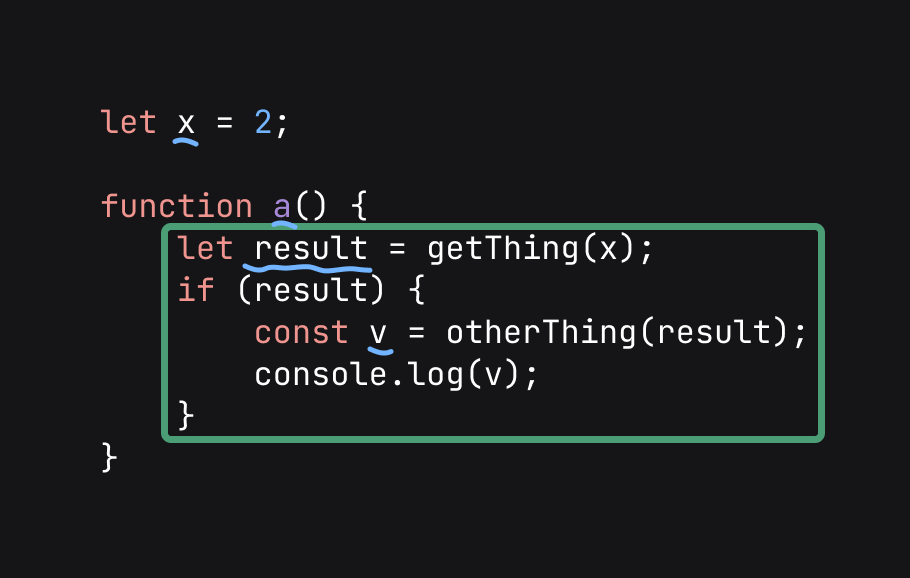
This includes:
- Names to types
- Names to variables
- The current value of a variable
- The current properties on objects
They also contain a reference to the parent. Which it can get properties from:
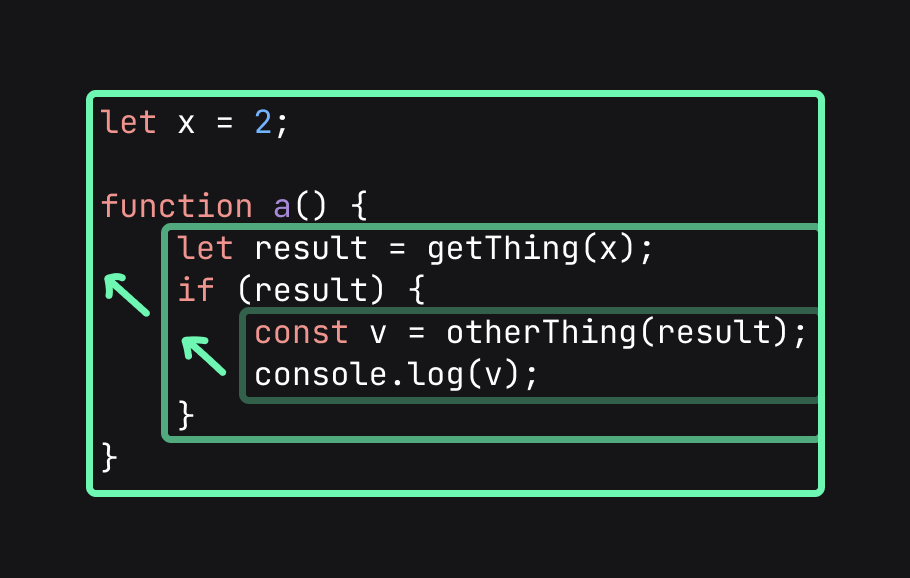
What kinds of contexts are there?
- Root
- Module
- Functions
- If and else blocks
- For statements
Every environment (other than root) has a field for the Scope. Scopes differentiate environments that are for a function body between if-else blocks (which we will see different behaviour for later).
It can get slightly more complex as it (will) include
function (input: MyObject | null) {
return input && otherValue
// ^^^^^^^^^^
}
function (input: MyObject | null) {
return input && otherValue
// ^^^^^^^^^^
}
Synthesizing the right-hand side of this logical expression (otherValue) is done in a new context. This is because it conditionally runs (because of short-circuiting with logical and), any effects here have to be separated and narrowing can because it is known that input has type null here.
The different contexts, GeneralContext and get_on_ctx!
There are two different types of contexts Root and Environment (aliases for Context<Root> and Context<environment::Syntax<'a>>). Root is the top-level environment, it doesn't have events or a parent. Environments on the other hand represent the standard contexts found for written code. They record events (and other information) and have a parent. You can see the code for all contexts here, and the code specific for environments (not root contexts) here.
This is structured using Rust generics and so can be a bit complex. To make it easier GeneralContext is a sum type of the two contexts. To get properties on it, you can use get_on_ctx!.
Looking up information with parents_iter
In JS information can be accessed in am above context
const x = 2;
function three() {
return x + 1;
// ^
// What is the value of `x` here
}
const x = 2;
function three() {
return x + 1;
// ^
// What is the value of `x` here
}
Context::parents_iter offers a way to walk up the parent chain to look for information.
Where are the properties of types?
One way to have an object type would be to do
struct InterfaceType {
name: String,
properties: HashMap<String, TypeId>
// ^^^^^^^^^^^^^^^^^^^^^^^
// Map properties to types
}
struct InterfaceType {
name: String,
properties: HashMap<String, TypeId>
// ^^^^^^^^^^^^^^^^^^^^^^^
// Map properties to types
}
However, the problem is that the value of properties is not always a global fact. In the two scopes
const x = {};
if (value) {
x.a = 2;
// here x.a = 2
} else {
x.a = 3;
// here x.a = 3
}
const x = {};
if (value) {
x.a = 2;
// here x.a = 2
} else {
x.a = 3;
// here x.a = 3
}
x.a has different values as shown in the comments.
This is not true for all facts, in the two scopes calling the function x has the same behaviour.
function x() { ... }
if (condition) {
x()
} else {
x()
}
function x() { ... }
if (condition) {
x()
} else {
x()
}
Calling x (the value not the reference) always yields the same as x (and that can differ).
Similar logic is done for the value variables, which are stored in variable_current_value.
So Ezno these are held under the context. While not implemented, prototypes and type narrowing will also work this way, being scoped to contexts rather than global.
This is done for all types for simplicity, including interfaces.
The variable and property facts applies to many other dynamic and static languages, not just JavaScript.
Scopes and dynamic scopes
As said before, every environment has a scope type. When looking for things between scopes, it needs to know whether the facts are constant between the scopes. For example
let x = 2;
if (condition) {
let y = x;
// ^
// x is always 2 here
}
let x = 2;
if (condition) {
let y = x;
// ^
// x is always 2 here
}
However for
let x = 2;
function func() {
let y = x;
// ^
// x may not be 2 here if it is assigned a different value before a `func` function call
}
let x = 2;
function func() {
let y = x;
// ^
// x may not be 2 here if it is assigned a different value before a `func` function call
}
and
let x = 2;
for (const item of myArray) {
let y = x;
// ^
// x can be different again, because of the following statement
x++
}
let x = 2;
for (const item of myArray) {
let y = x;
// ^
// x can be different again, because of the following statement
x++
}
The first example of if is a static scope. Whereas for the function and for scopes they are considered dynamic scopes and so the context logic does different behaviour in many cases when crossing these contexts.
The main global structures: CheckingData, DiagnosticsContainer, TypeMappings and TypeStore
CheckingDataholds most information for a project it holdsDiagnosticsContainerandTypeStoreDiagnosticsContaineris a container of Diagnostics that includes errors, warnings and general information.TypeStorestores all the types- Currently, types are referenced using
pub struct TypeId(u16)where the integer references an index into aVec<Type> - This is a sort of arena. It means that types can safely reference themselves. While it does hold a lot of memory, types are needed between passes, so there isn't a lot to be dropped. It also means that it is easy to be serialized to a format that can be stored between runs to make checking times improved.
- This is a work in progress, it will be improved to split types by their file/source and probably other ways.
- Currently, types are referenced using
Type and TypeId
One thing is types are immutable, once they are registered the actual Type doesn't change! There are lots of kinds of Types
The basics are:
- Named types (interfaces)
- Aliases
- Or (union types), these mean that they (inclusively) either have the properties on the left or on the right
- And (intersection types), these mean it satisfies the properties on the left and the right
- Constants/terms
- Functions
- Objects
- Root poly (parameters)
- Constructors (usage of parameters)
Categorising types
There are many types that are considered restrictions/general spaces. These cannot be variable or property current values!
- Interfaces
- Intersection and unions
- Functions from type annotation
There are three types that are considered constants and so have a consistent total known behaviour
Type::Constantwhich representsnumbers,strings, andbooleans- Functions defined in the source
- Immutable objects and objects where access does not cross a dynamic scope.
The bridge between the two are poly-types
Parameter types (poly-types)
Constants are great however, places where something can't be represented as a constant are known as poly-types. Function parameters are one example, also explicit generics.
Parameters
Alongside explicit function parameters (such as x in function func(x) { ... }) there are other places in JS where a function can be parameterized. For example, closed over variables and this. These are the most common poly-types.
Constructors, the higher poly-types
Parameters are root poly-types. All that is known is the origin. However, we want to carry more information. This is where constructors come in, they wrap any poly type with additional information about its usage.
Closed and open poly-types
The standard poly-type is closed. These are types such that a set of specializations can be formed.
let a = 1;
function id<T>(t: T) {
return { t, a }
}
id("hi");
a++;
id("hello");
let a = 1;
function id<T>(t: T) {
return { t, a }
}
id("hi");
a++;
id("hello");
After checking the above script, a in the function body is specialized as 1 and 2 and T is specialized as "hi" and "hello". In other words, we know a set of values that poly type takes throughout the life of the script.
The tracing problem
When evaluating let p = document.body, document can take on a range of values and so can document.body. So in this way they are similar to regular function parameters. In fact, if JS had a main function without global variables it might look like:
function main(document, fetch, ...) {
// ...
}
function main(document, fetch, ...) {
// ...
}
So variables such as document are considered similar to parameters. These are known as open poly-types. The open refers to the fact that what they are specialized to is out of the range of the checker. After checking, closed poly-types have a finite set of types they are specialized as. On the other hand, open have an unknown set.
This is still experimental and will probably be changed in some way at some point. Some open poly traces are completely useless, such as
Math.
Is subtype
The type_is_subtype function compares types. It is used when checking an argument is valid against a parameter, or a value assigned to variable meets it's constraint. It returns the following result:
#[derive(Debug)]
pub enum SubTypeResult {
IsSubtype,
IsNotSubType(NonEqualityReason),
}
#[derive(Debug)]
pub enum SubTypeResult {
IsSubtype,
IsNotSubType(NonEqualityReason),
}
The function checks whether the RHS has all the 'properties' of the LHS.
Specialisation
In TypeScript (and Rust), call site generics can be inferred. This means that when calling a function with generic type parameters, the type parameters can be derived from the types of arguments if they were not already explicitly given
function identity<T>(a: T) {
return a
}
const x = identity(console)
function identity<T>(a: T) {
return a
}
const x = identity(console)
The other thing is that in Ezno, every function parameter (apart from functions behind a generic) is generic (cascade information). So these auto generics cannot be explicit set for parameters not explicitly generic.
Ezno could resolve these types by scanning the argument list first. Instead during equality, while checking it adds these values to a SeedingContext.
Constraint inference
This is something being worked out. Most parameters have a fixed and known space they operate in. However, to enable full checking on sources without annotation, this restriction could be generated from its usage. See more in the issue.
const sinPlusOne = (x) => {
return Math.sin(x) + 1
// ^^^^^^^^^^^
// This call requires `x` to be a number. The poly
// constraint needs to be modified to reflect this
}
const sinPlusOne = (x) => {
return Math.sin(x) + 1
// ^^^^^^^^^^^
// This call requires `x` to be a number. The poly
// constraint needs to be modified to reflect this
}
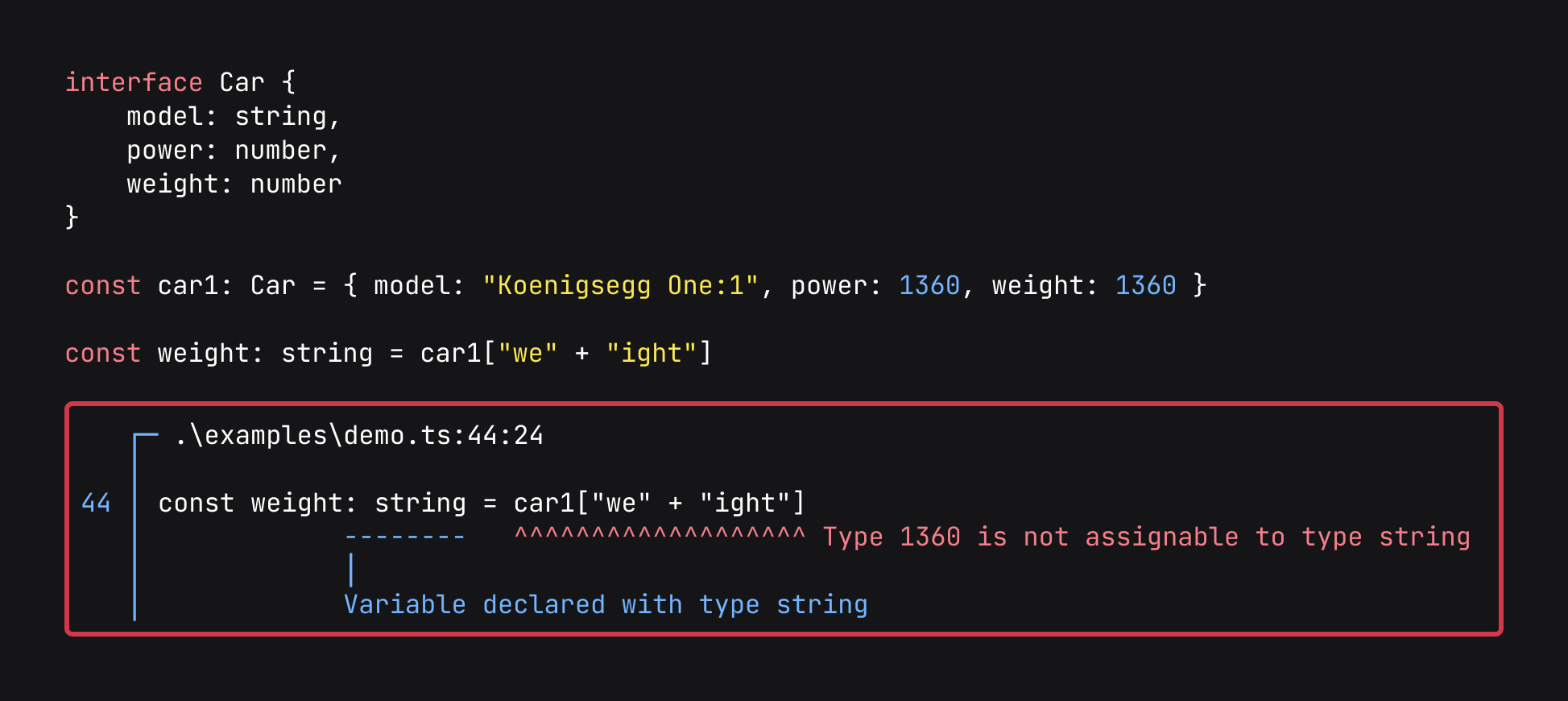
Constant functions
Some functions have a constant identifier (as shown above in the return annotation). Functions with this try and evaluate a result using custom Rust code. The Rust code only works for constants and so if it can't compute a result it will fail and resort back to specializing the return type of the function.
This is what enables the following error to be caught
Events and effects
Events track mutations and other actions the code does. There are many kinds of events that can happen, the simple ones are assignments and function calls.
Events are the general term for these. When added to a FunctionType these are referred to as (side) effects of a function. You can see the events being pulled here.
Throw and try-catch
Following on from a previous post, I managed to get try-catch statements to work and be type-safe 🎉
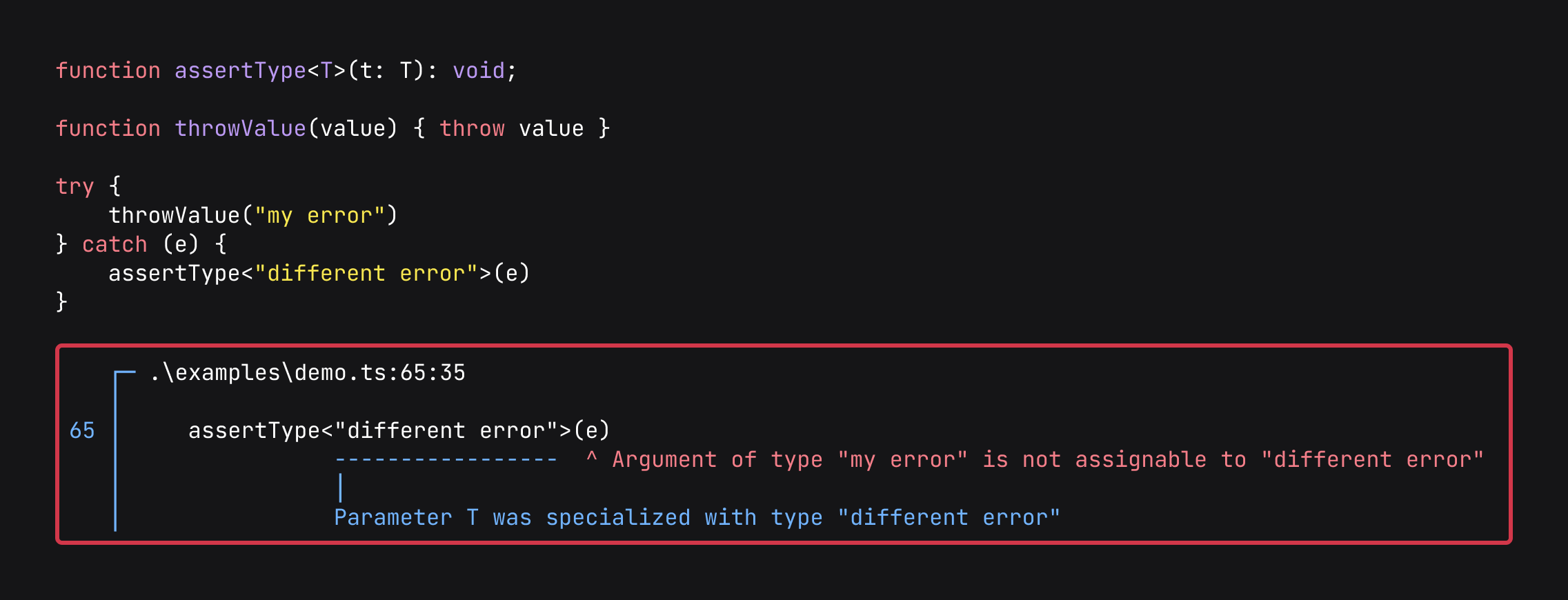
While most of the time Error is thrown, this covers every type. With dependent string types you also get the message of what types are thrown.
The above is a bit more complicated because it is throwing a parameter type. The actual value is found through type specialisation (in the same way that let x: 2 = (a => a)(2) works). The types of errors thrown are found using this function (which again is work-in-progress).
More benefits of the events system
- They reuse types so can be specialized like the above
- Catch a lot of side effect cases, which can give more information rather than resorting to unknown-ness
- Calling functions to track what functions are called, which allows tree shaking of associated functions (functions under objects)
- They could be used as IR for generating more optimized output
Some extras
Hoisting passes
Currently work in progress, but you can see how interfaces are checker before functions which is checked before any other structure in hoist_statements
Printing types
Turning types into strings is done here.
This also has to handle some other things:
- Recording what types have been printed types to not stack overflow in the case of cyclic types
Diagnostics, registering errors and warnings
diagnostics.rs has a long list of errors and how to turn them into general Diagnostics which can be printed to the CLI or presented in a LSP.
Developing
If you are interested in contributing, read CONTRIBUTING.md.
What is next
You can read more standing issues on GitHub issues.
There is still more to do
- Ezno's own CLI, with the CLI REPL
- Finishing off the LSP (language service provider) with an associated VS Code extension to get type-checking results and helpers inside an editor.
- Using the types in optimising compilers!
- Some more experimental features in terms of syntax and things 👀
- Finishing Ezno's own parser, it is 95% there, so it would be nice to round it off
However I am now taking a break
Unfortunately, I have other priorities for the next two months, so I can't spearhead additions and fixes. I will be around though to respond to certain things but development will be slower.
Incredibly grateful for current sponsors. Any contributions including one-time are important for this project to keep going. For now, GitHub sponsors is looking like the easiest way to do this.
Hopefully, I can keep this going as a chill experimental project without strings attached that I can keep improving part-time!